실습과정
- Lambda 함수를 작성하여 Athena가 S3의 processed_data에서 Hits 별 Top5 Popular Songs를 쿼리하여 가져오는 코드를 호스팅

AWS Athena : 표준 SQL을 사용하여 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스
(Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함)
AWS Lambda : 서버를 관리하지 않고도 코드를 실행할 수 있는 AWS에서 제공하는 서버리스 컴퓨팅 시스템
(서버리스 : 서버가 없는 것이 아니라 서버에 대한 요청을 처리하는 로직을 함수 단위로 정의하여 요청이 들어올 때마다 함수를 호출하는 방식)
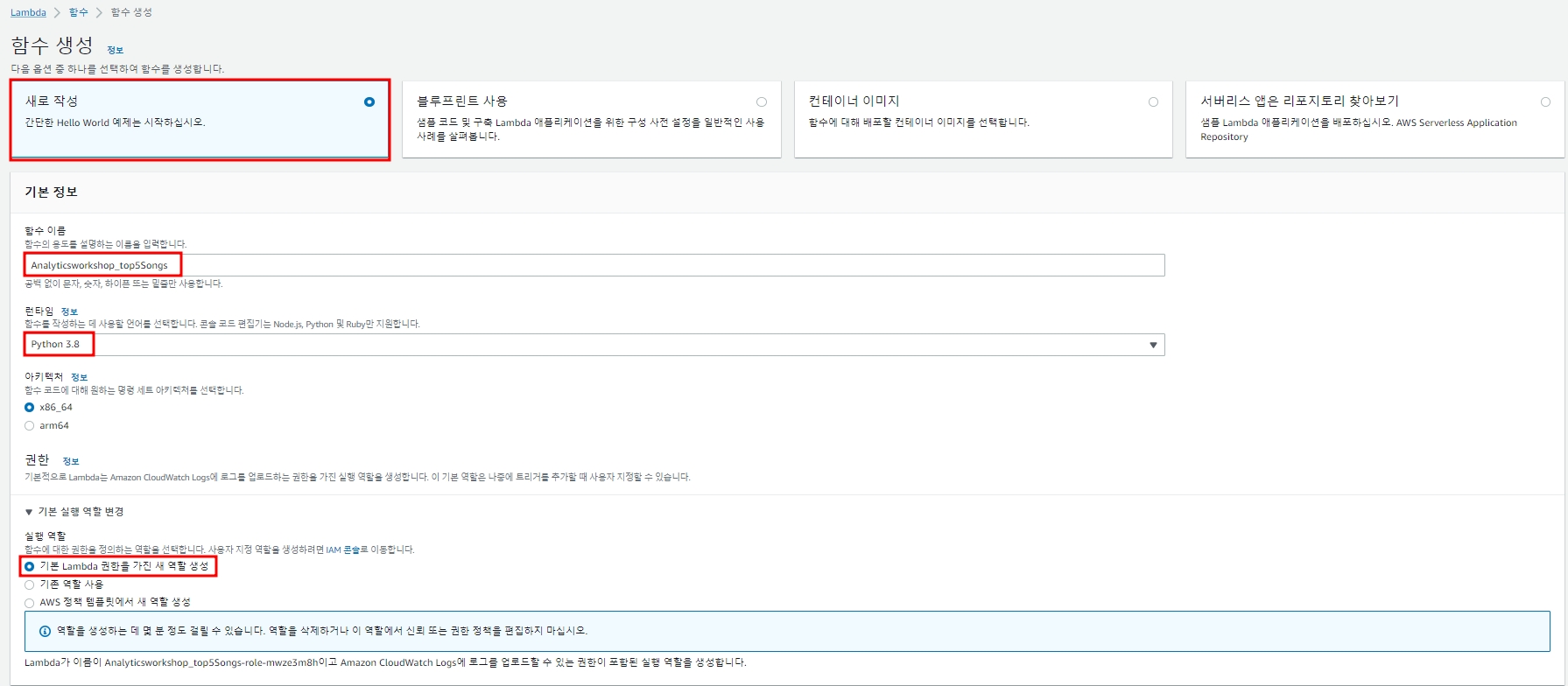
1. Lambda 함수 생성
Lambda 서비스를 사용하기 위해 lambda 함수를 생성한다.
- 리전 us-east-1(버지니아 북부) 확인
- 함수 생성 버튼 클릭

- 함수 이름 : Analyticsworkshop_top5Songs
- 런타임 : Python 3.8
- 기본 실행 역할 변경 - 기본 Lambda 권한을 가진 새 역할 생성
- 함수 생성
2. Lambda 함수 작성
방금 전에 만든 Lambda 함수에 대한 코드를 작성한다.

import boto3
import time
import os
# Environment Variables
DATABASE = os.environ['DATABASE']
TABLE = os.environ['TABLE']
# Top X Constant
TOPX = 5
# S3 Constant
S3_OUTPUT = f's3://{os.environ["BUCKET_NAME"]}/query_results/'
# Number of Retries
RETRY_COUNT = 10
def lambda_handler(event, context):
client = boto3.client('athena')
# query variable with two environment variables and a constant
query = f"""
SELECT track_name as \"Track Name\",
artist_name as \"Artist Name\",
count(1) as \"Hits\"
FROM {DATABASE}.{TABLE}
GROUP BY 1,2
ORDER BY 3 DESC
LIMIT {TOPX};
"""
response = client.start_query_execution(
QueryString=query,
QueryExecutionContext={ 'Database': DATABASE },
ResultConfiguration={'OutputLocation': S3_OUTPUT}
)
query_execution_id = response['QueryExecutionId']
# Get Execution Status
for i in range(0, RETRY_COUNT):
# Get Query Execution
query_status = client.get_query_execution(
QueryExecutionId=query_execution_id
)
exec_status = query_status['QueryExecution']['Status']['State']
if exec_status == 'SUCCEEDED':
print(f'Status: {exec_status}')
break
elif exec_status == 'FAILED':
raise Exception(f'STATUS: {exec_status}')
else:
print(f'STATUS: {exec_status}')
time.sleep(i)
else:
client.stop_query_execution(QueryExecutionId=query_execution_id)
raise Exception('TIME OVER')
# Get Query Results
result = client.get_query_results(QueryExecutionId=query_execution_id)
print(result['ResultSet']['Rows'])
# Function can return results to your application or service
# return result['ResultSet']['Rows']
boto3를 사용하여 Athena 클라이언트에 엑세스한다.
Boto는 Python용 Amazon Web Services SDK이다. 이를 통해 Python 개발자는 EC2 및 S3와 같은 AWS 서비스를 생성, 구성, 관리할 수 있다.
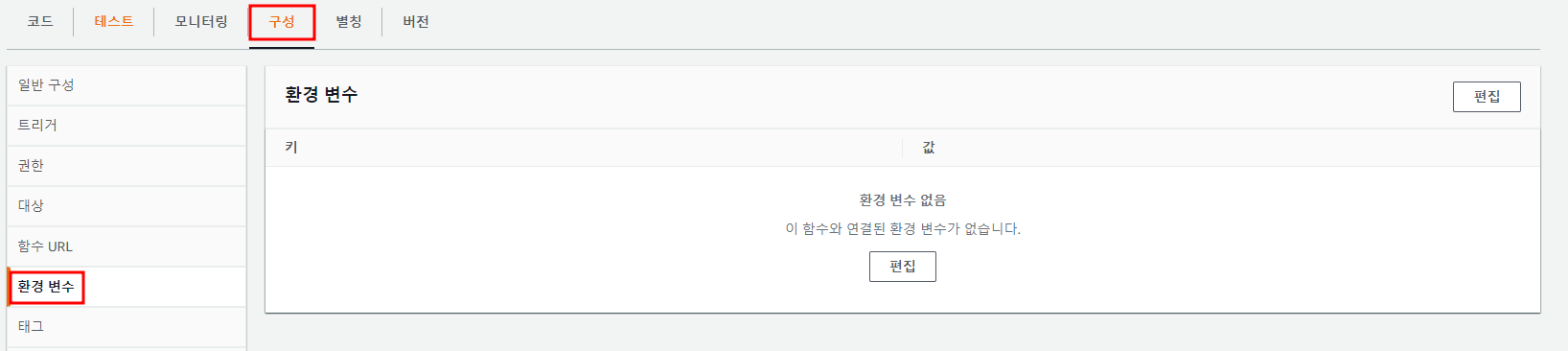
3. 환경 변수 설정
Lambda 함수에 대한 환경 변수를 사용하면 코드를 변경하지 않고도 설정을 함수 코드 및 라이브러리에 동적으로 전달할 수 있다.
- 구성 탭에서 환경변수 선택
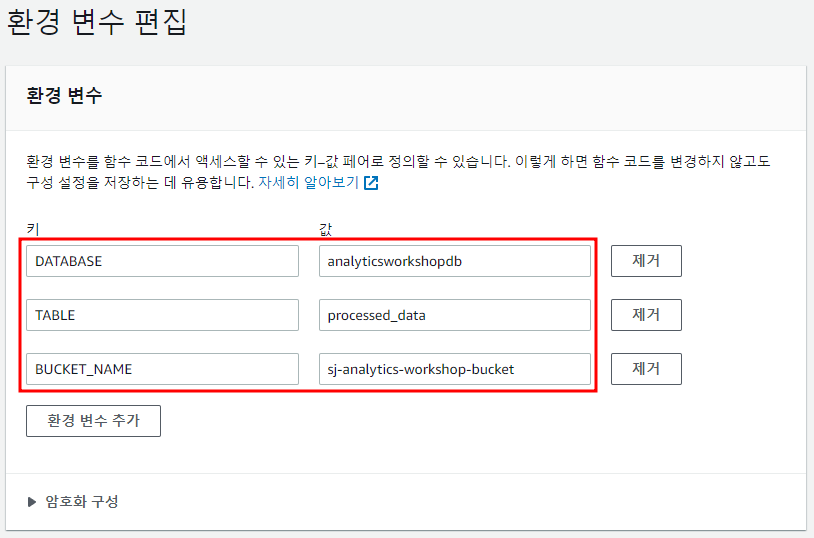
편집을 선택하여 3가지 환경 변수 추가
- 키 : DATABASE, 값 : analyticsworkshopdb
- 키 : TABLE, 값 : processed_data
- 키 : BUCKET_NAME, 값 : sj-analytics-workshop-bucket
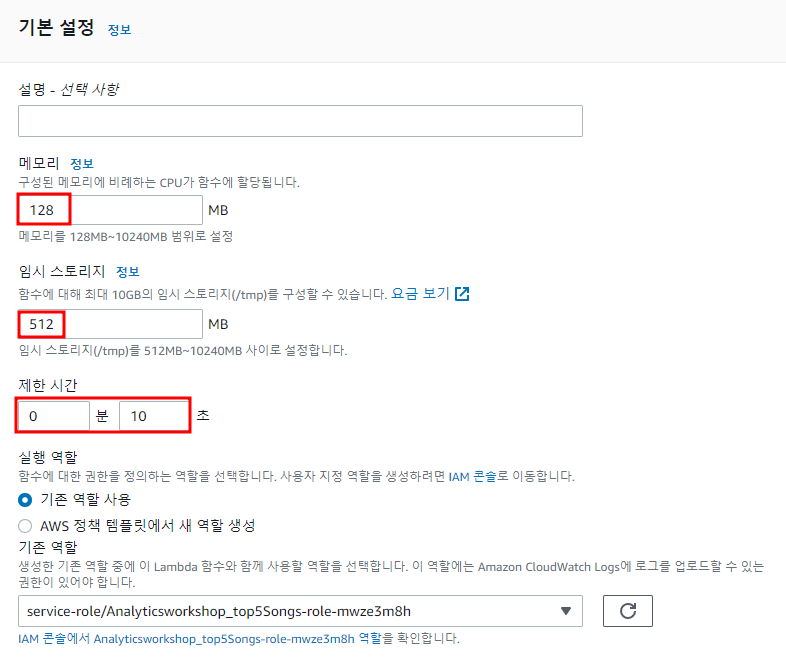
일반구성 탭에서 편집

- 메모리 : 128MB
- 임시 스토리지 : 512MB
- 제한 시간 : 0분 10초
4. 실행 역할 설정
구성 탭에서 권한 클릭
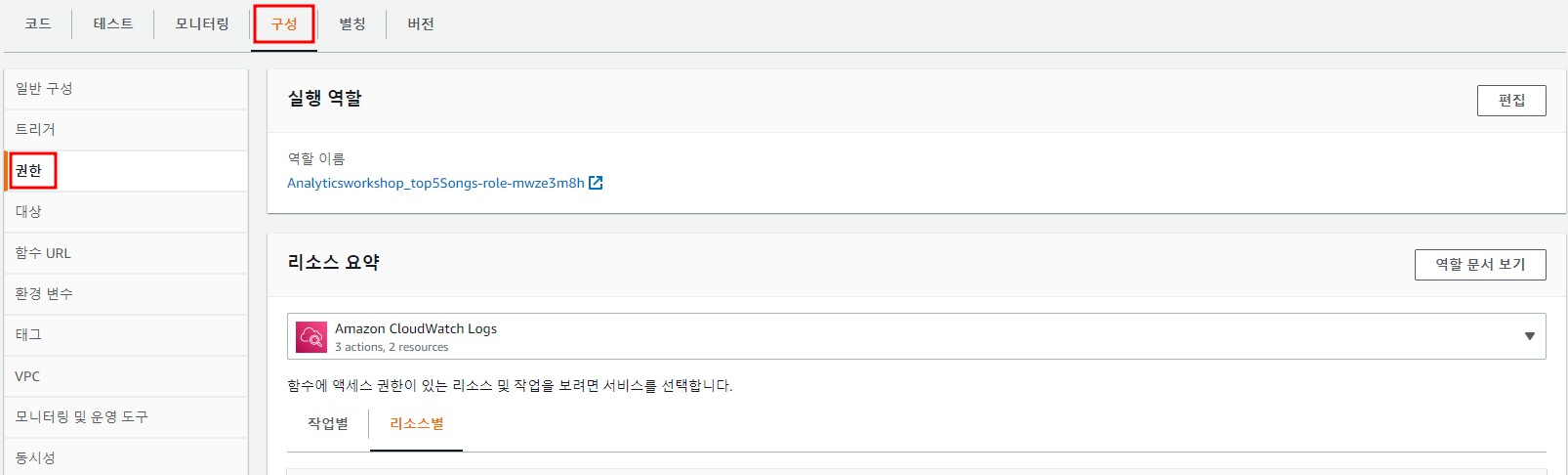
실행 역할의 역할이름을 클릭하여 권한 추가
- AmazonS3FullAccess
- AmazonAthenaFullAccess


5. 테스트 이벤트 구성
이제 함수를 테스트 할 준비가 됐다. 함수 코드 소스 섹션에서 Deploy를 클릭하여 함수를 배포한다.

다음으로 새로 생성된 Lambda 함수의 실행 결과를 확인하기 위해 Dummy 테스트 이벤트를 구성해보자.
- 코드 소스 아래에서 Test를 클릭한다.
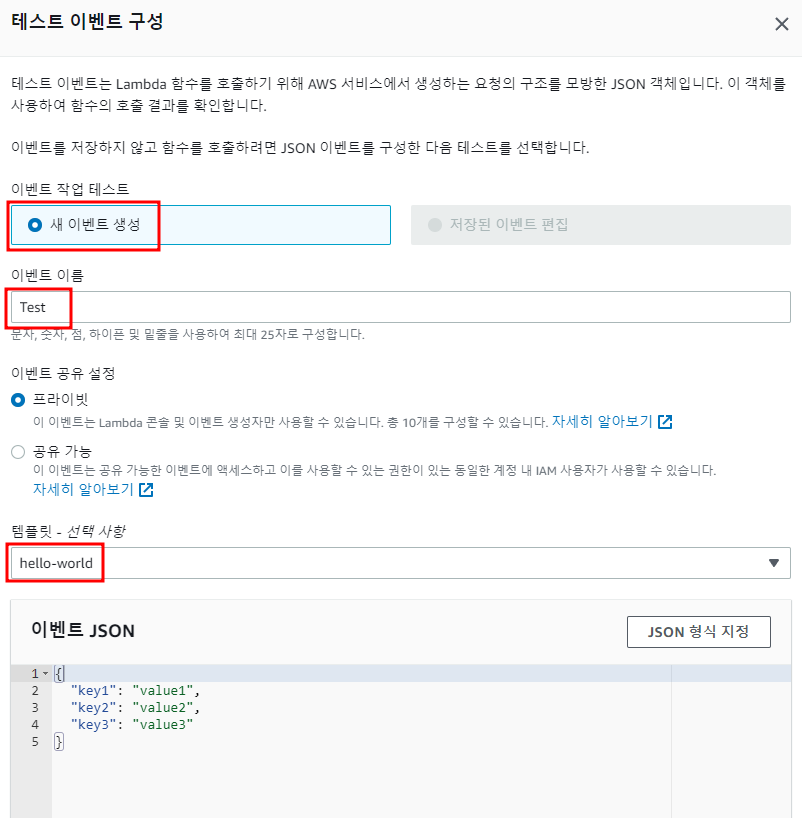
- 테스트 이벤트를 구성하는 창이 나타난다.
- 새 이벤트 생성
- 이벤트 이름 : Test
- 이벤트 템플릿 : hello-world
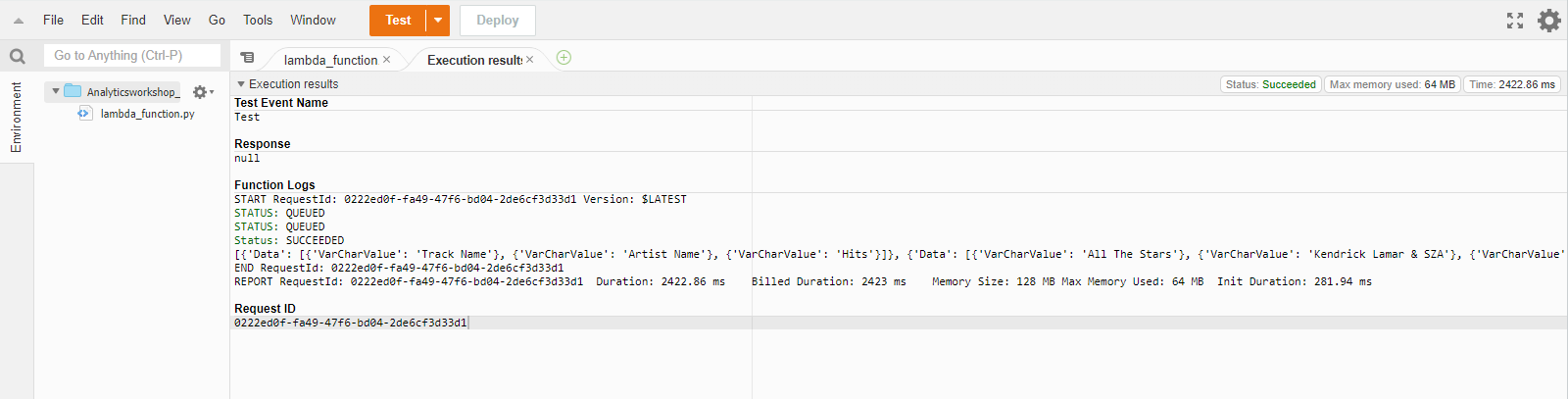
- Test 다시 클릭
- 새로 생긴 Execution Result 섹션에서 json 형식의 출력을 볼 수 있다.
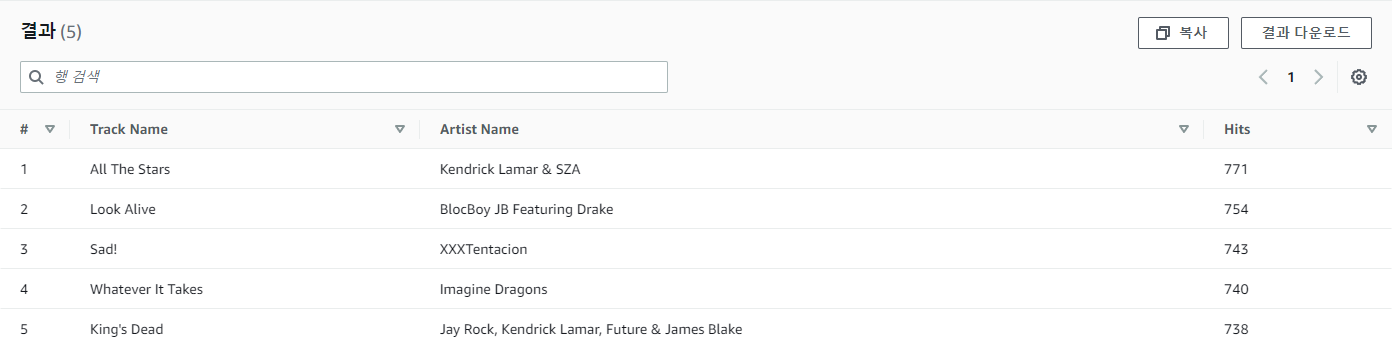
6. Athena를 통한 확인
Athena를 통해 결과를 확인한다.
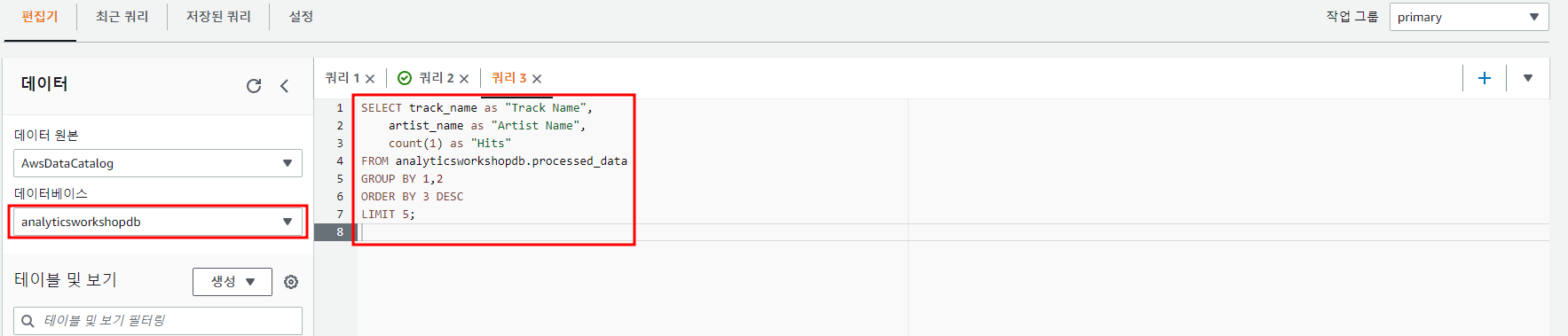
SELECT track_name as "Track Name",
artist_name as "Artist Name",
count(1) as "Hits"
FROM analyticsworkshopdb.processed_data
GROUP BY 1,2
ORDER BY 3 DESC
LIMIT 5;
'AWS' 카테고리의 다른 글
| AWS기반 데이터 분석 파이프라인 구축[8] (0) | 2022.10.19 |
|---|---|
| AWS기반 데이터 분석 파이프라인 구축[7] (0) | 2022.10.19 |
| AWS기반 데이터 분석 파이프라인 구축[5] (0) | 2022.10.12 |
| AWS기반 데이터 분석 파이프라인 구축[4] (0) | 2022.10.07 |
| AWS기반 데이터 분석 파이프라인 구축[3] (1) | 2022.10.04 |