실습과정
- Amazon Athena의 표준 SQL 쿼리를 사용하여 Glue 카탈로그에 등록된 데이터를 탐색
- Athena를 사용하여 Amazon Quicksight에서 대시보드/시각화를 구축

AWS Athena : Amazon Athena는 표준 SQL을 사용하여 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스이다.
(Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불함.)
AWS Quicksight : Amazon QuickSight는 아마존이 제공하는 서버리스 매니지드 BI 상품이다. 특정 데이터에 대한 시각화 대시보드를 생성하고 다른 사용자와 공유할 수 있다.
1. 쿼리 결과를 저장할 S3 버킷 만들기
Amazon Athena에 접속한 뒤 쿼리 결과를 저장할 S3 버킷을 먼저 만들어야 하므로 다음 단계를 따라 설정한다.
- 저장될 버킷 생성 : sj-query-results-bucket
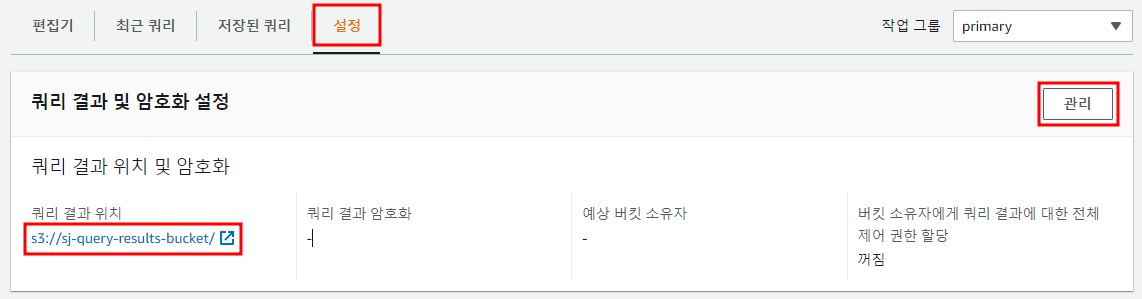
- 버킷을 생성한 후 Athena 콘솔로 돌아가서 콘솔 왼쪽 상단의 설정 클릭 후 관리 클릭
- 방금 생성한 버킷의 이름과 마지막에 '/'를 포함하여 입력
- Save
2. Athena를 사용하여 변환된 데이터 탐색
데이터 원본 : AwsDataCatalog를 선택하여 AWS Glue 카탈로그에 접근
데이터베이스 : analyticsworkshopdb
아래 쿼리 실행
SELECT artist_name,
count(artist_name) AS count
FROM processed_data
GROUP BY artist_name
ORDER BY count desc


3. Amazon Quicksight 계정 가입
Amazon Quicksight 콘솔로 들어간다.
- Enterprise 선택 후 Continue 클릭



데이터 세트를 클릭하여 우측 상단의 새 데이터 세트를 클릭해준다. .
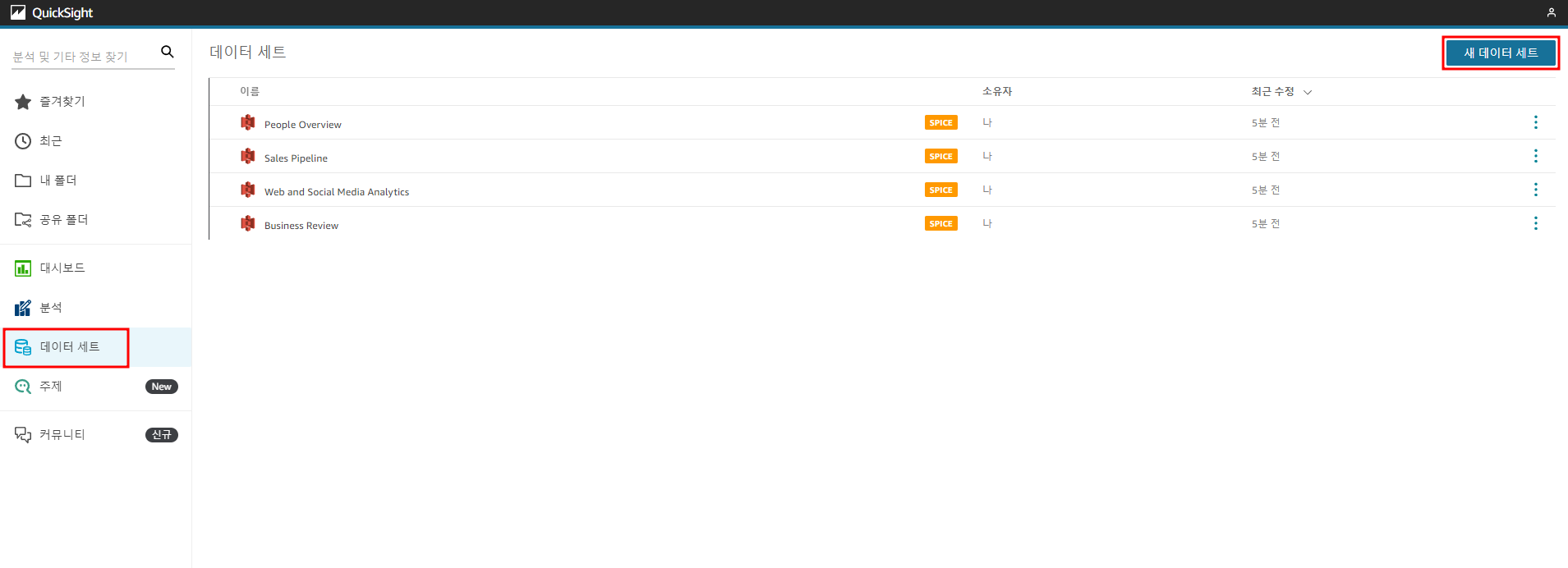
Athena 선택

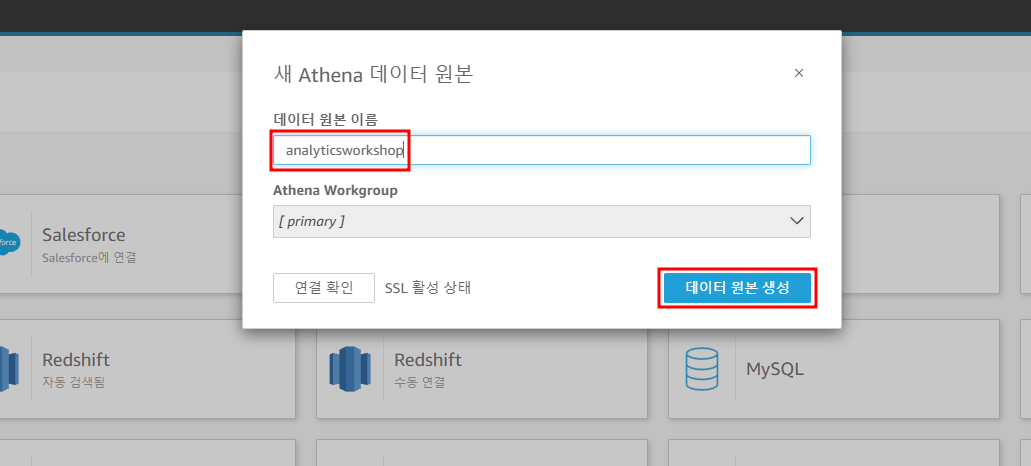
데이터 원본 이름 설정하고 데이터 원본 생성
데이터 원본 이름 : analyticsworkshop
Athena Workgroup : primary
테이블 선택 화면으로 들어오면,
카탈로그 : AwsDataCatalog
데이터베이스 : analyticsworkshopdb
테이블 : processed_data
를 선택한다.

데이터 세트 생성 완료하기로 들어오게 되면,
SPICE for quicker analytics를 선택하여 프로세싱한다. (시각화에 걸리는 시간을 줄여주는 AWS 인메모리 엔진)

4. Amazon Quicksight를 사용하여 시각화 구축
데이터 세트가 생성되었다면,
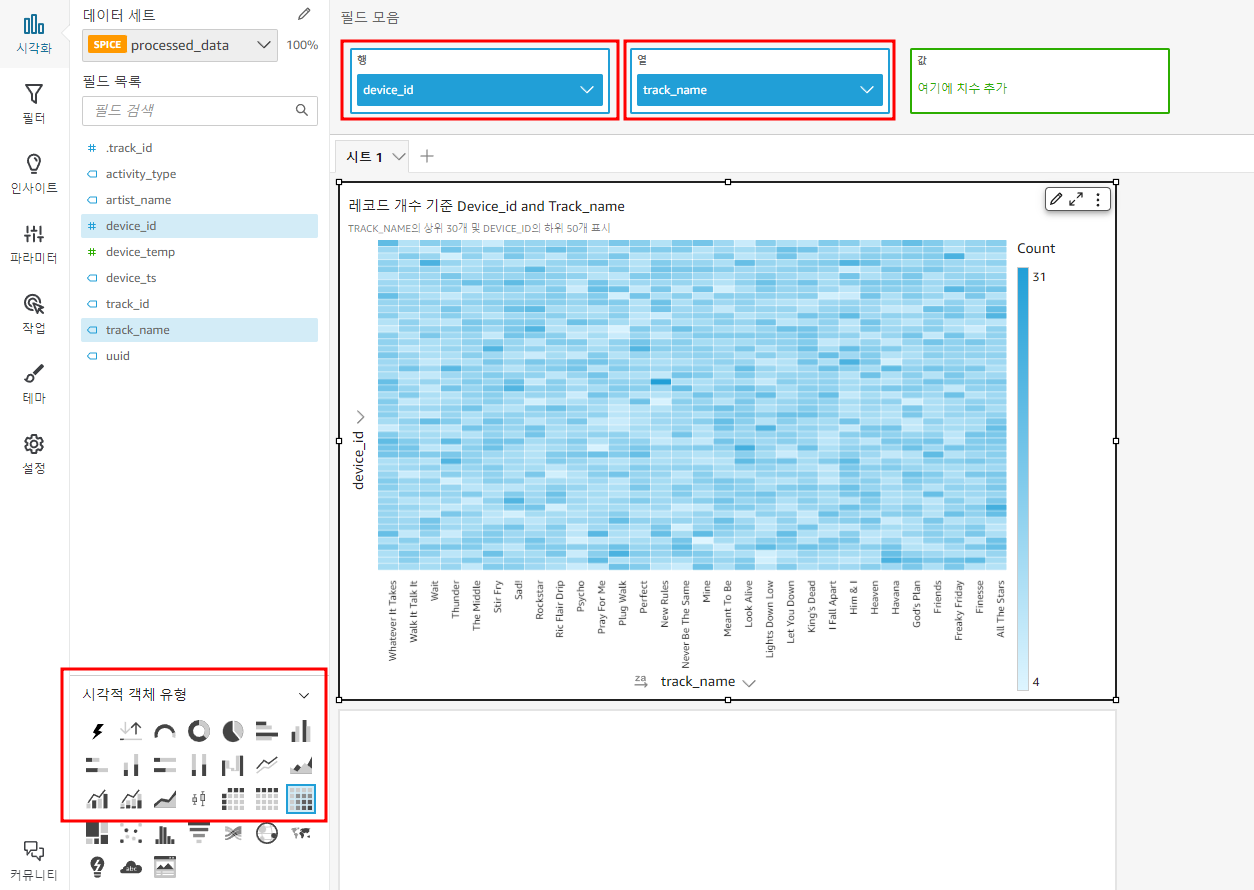
- 시각적 객체유형 : 히트맵
- 행 : device_id
- 열 : track_name
위와 같은 설정을 통해 '어떤 사용자가 반복적으로 트랙을 듣고 있는지'를 시각화한다.
- 시각화 화면 추가 : 왼쪽 상단의 +추가버튼에서 시각적 객체 추가
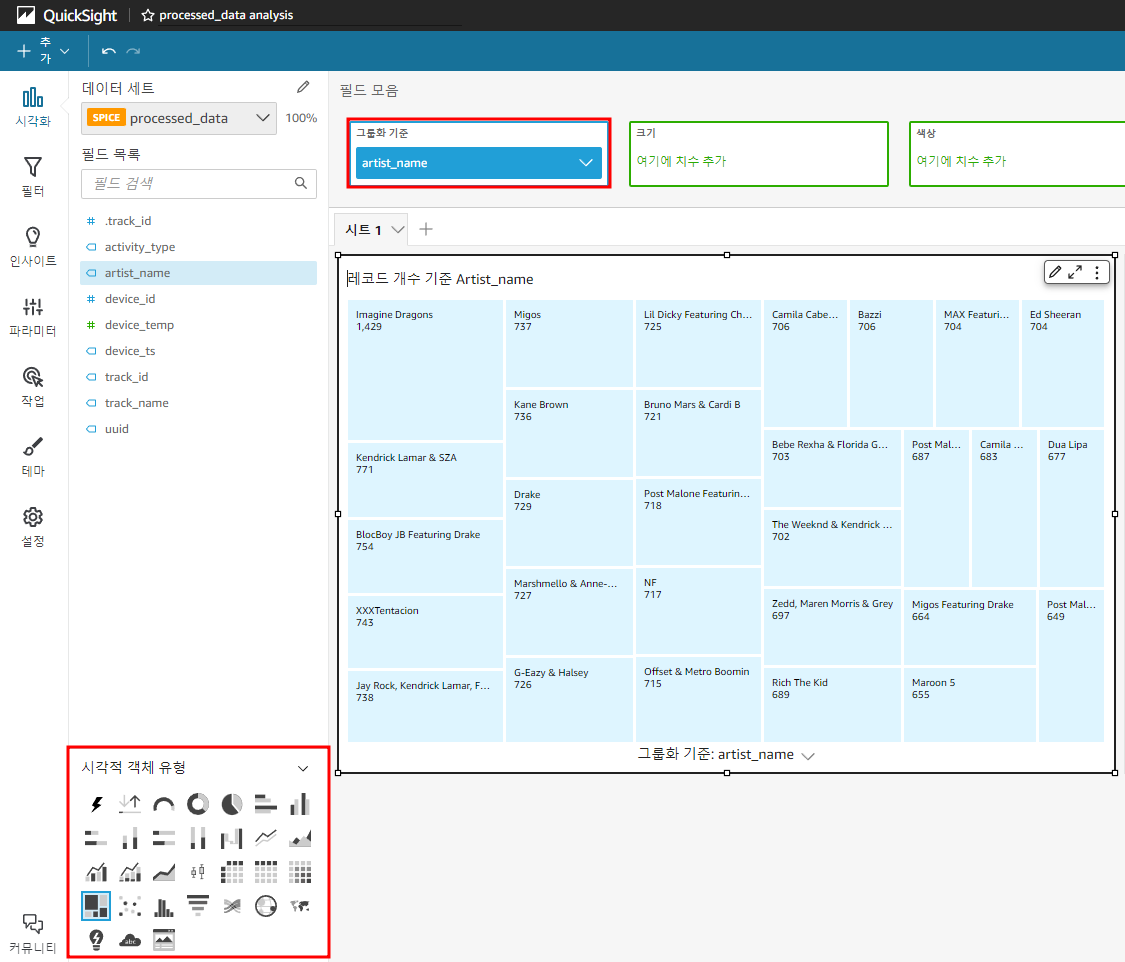
- 시각적 객체 유형 : 트리맵
- 그룹화 기준 : artist_name
위와 같은 설정을 통해 '가장 많이 연주된 아티스트'를 시각화한다.
'AWS' 카테고리의 다른 글
| AWS기반 데이터 분석 파이프라인 구축[7] (0) | 2022.10.19 |
|---|---|
| AWS기반 데이터 분석 파이프라인 구축[6] (0) | 2022.10.18 |
| AWS기반 데이터 분석 파이프라인 구축[4] (0) | 2022.10.07 |
| AWS기반 데이터 분석 파이프라인 구축[3] (1) | 2022.10.04 |
| AWS기반 데이터 분석 파이프라인 구축[2] (0) | 2022.09.30 |