맵리듀스(MapReduce)
대용량 데이터 처리를 위한 분산 프로그래밍 모델
맵리듀스 프레임워크를 이용하면 대규모 분산 컴퓨팅 환경에서 대량의 데이터를 병렬로 분석 가능하다. 프로그래머가 직접 작성하는 맵과 리듀스라는 두 개의 메소드로 구성된다.
흩어져 있는 데이터를 수직화하여, 그 데이터를 각각의 종류별로 모으고(Map) → 필터링과 sorting을 거쳐 데이터를 뽑아내는(Reduce) 분산처리 기술과 관련 프레임워크를 의미한다.
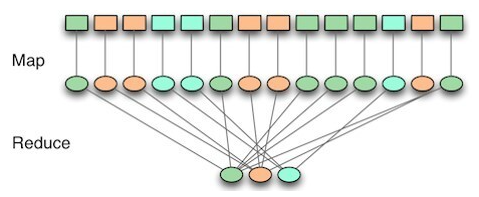
맵(Map)
흩어져 있는 데이터를 연관성 있는 데이터들로 분류하는 작업(key, value의 형태)
리듀스(Reduce)
Map에서 출력된 데이터에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업
맵리듀스 잡(MapReduce Job) : Client 수행 작업 단위
클라이언트가 수행하려는 작업단위로써, 입력 데이터, 맵리듀스 프로그램, 설정 정보로 구성되어 있다.
하둡은 Job을 Map Task와 Reduce Task로 작업을 나누어서 실행한다.
맵리듀스 시스템은 Client, JobTracker, TaskTracker로 구성된다.

클라이언트 : 분석하고자 하는 데이터를 Job의 형태로 JobTracker에게 전달
잡 트래커 : 네임노드에 위치. 하둡 클러스터에 등록된 전체 Job을 스케줄링하고 모니터링
테스크 트래커 : 데이터노드에서 실행되는 데몬. Task를 수행하고, 잡 트래커에게 상황 보고
'Hadoop' 카테고리의 다른 글
| Hadoop 설치 (0) | 2022.12.06 |
|---|---|
| 하둡 분산형 파일 시스템(Hadoop Distributed File System, HDFS) (0) | 2022.09.21 |
| 하둡 에코시스템(Hadoop Ecosystem) (1) | 2022.09.21 |