1. ubuntu에 open-jdk 설치
1) 패키지 갱신
sudo apt update
2) open jdk 설치
sudo apt install openjdk-8-jdk -y
2. hadoop용 계정 생성
1) localhost와 ssh통신을 위한 openssh-server open-client 설치
sudo apt install openssh-server openssh-client -y
2) 계정 추가 및 비밀번호 설정
sudo adduser hdoop
3) hdoop 계정으로 접속
su - hdoop
4) hadoop 유저를 위한 비밀번호 없는 ssh통신 가능하게 하기
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
ssh localhost
3. hadoop 설치
1) root 디렉토리로 이동
cd ~
2) hadoop 공식 홈페이지에서 hadoop 다운로드
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzcf) 2022.12 기준 hadoop 최신 버전인 hadoop 3.3.4 버전을 다운로드 했다.
3) hadoop 설치 파일 압축 해제
tar xzf hadoop-3.3.4.tar.gz
4) hadoop 환경 변수 설정(.bashrc 파일 수정)
nano .bashrc위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.
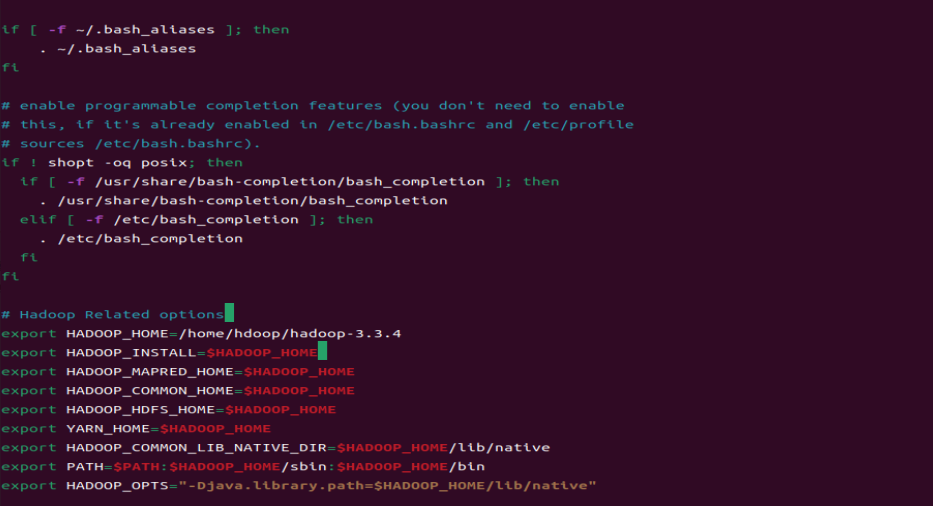
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.3.4
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
5) hadoop 환경 변수 설정한 것 적용
source ~/.bashrc
6) hadoop-env.sh 파일 편집(yarn, HDFS, MapReduce 세팅에 관한 파일)
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.

export JAVA_HOME=/usr/lib/jvm/java-8-openjsk-amd64
아래 명령어를 통해 java path를 확인한다.
which javac
readlink -f /usr/bin/javac
7) core-site.xml 편집(HDFS와 Hadoop 핵심 property들을 정의하는 파일)
nano $HADOOP_HOME/etc/hadoop/core-site.xml위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.
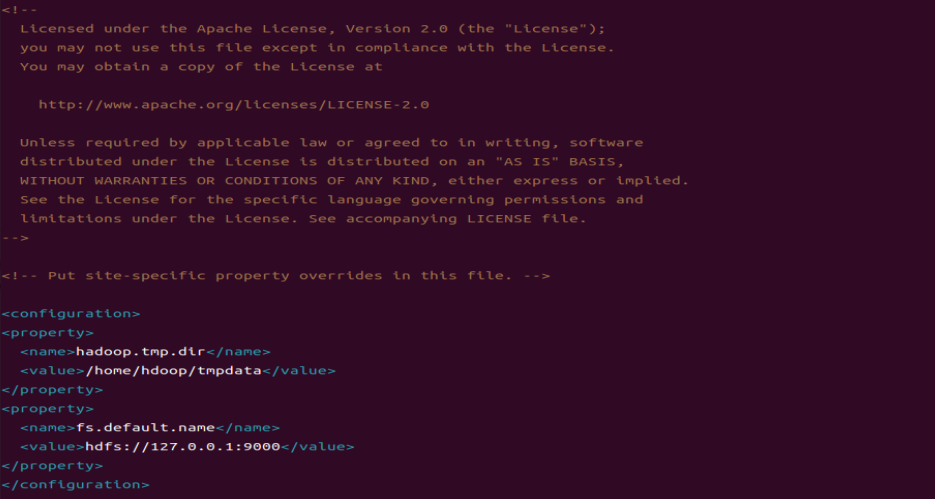
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>저장 후 tmpdata 디렉토리를 생성한다.
mkdir tmpdata
8) hdfs-site.xml 파일 편집(네임 노드와 데이터 노드의 저장소 디렉토리를 설정하는 파일)
nano $HADOOP_HOME/etc./hadoop/hdfs-site.xml위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.

<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
9) mapred-site.xl 파일 편집(mapreduce파일 값을 정의하는 파일)
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
10) yarn-site.xml 파일 편집(YARN 관련 세팅 파일)
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml위 명령어를 치고, 가장 아래로 내려가 아래 텍스트를 작성하고 저장한다.


<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8089</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
11) 네임노드 초기화
hdfs namenode -format
12) 하둡 클러스터 시작
hadoop-3.3.4/sbin/start-dfs.sh
hadoop-3.3.4/sbin/start-yarn.sh
jps
'Hadoop' 카테고리의 다른 글
| 맵리듀스(MapReduce) (0) | 2022.09.21 |
|---|---|
| 하둡 분산형 파일 시스템(Hadoop Distributed File System, HDFS) (0) | 2022.09.21 |
| 하둡 에코시스템(Hadoop Ecosystem) (1) | 2022.09.21 |